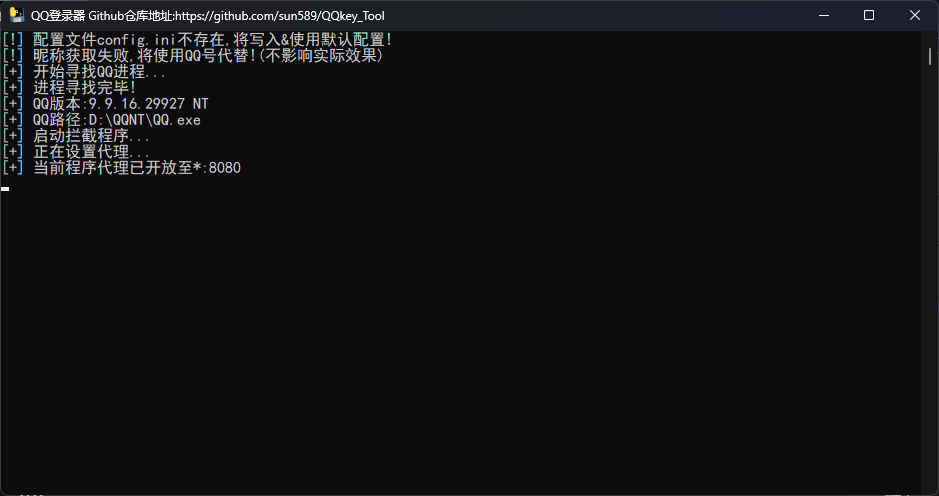
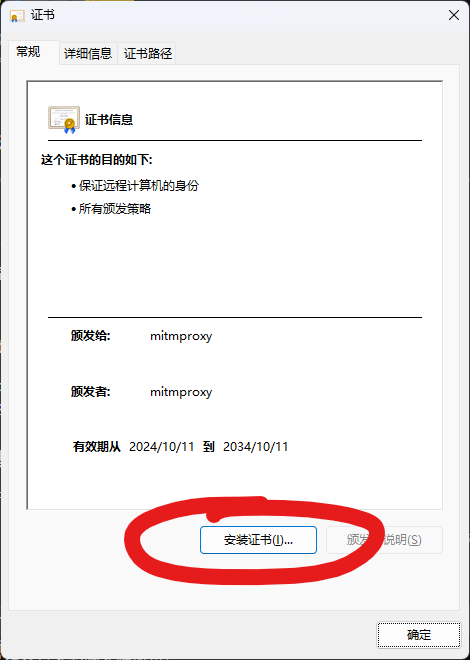
- gen6.2.hdf5 The Keras emotion detection model.
- data_from_fer_dataset.py Read from fer2013.csv and save images as jpeg files with labels.
- category_maker.py Make a training compatible file structure and copy image files to corresponding files. Images are classified by “train, validation, test” groups, and futher classified by emotions.
- train.py Train the model. There are a lot of things to configure, so check the main method to set command line args.
- test.py Different from the standard way of testing, this gives more information (information on accuracy of individual emotions).
- preprocessor.py Preprocess images before training. For each input image, add random crop, flip, noise, blur, and changes contrast.
- /models Contains the base model and the customized model.
The test result of this model on FER-2013 dataset. The dataset contains wild faces with emotion labels (harder to interpret). Distribution is a list, show how many images are predicted as each emotion of the 6 emotions. The order of distritution is the same of the order in column label. This result is for generation 5. Generation 6 achieves 68% accuracy.
| label | num image | accuracy | avg confidence | distribution |
|---|---|---|---|---|
| angry | 771 | 0.4396887159533074 | 0.43960431218956386 | [339, 0, 95, 125, 158, 54] |
| disgust | 78 | 0.0 | 0.0 | [40, 0, 8, 4, 18, 8] |
| happy | 1307 | 0.8500382555470544 | 0.8498112596211336 | [20, 0, 1111, 68, 77, 31] |
| neutral | 909 | 0.6105610561056105 | 0.6103332342742551 | [34, 0, 123, 555, 175, 22] |
| sad | 908 | 0.5770925110132159 | 0.5771962182550251 | [60, 0, 112, 176, 524, 36] |
| surprised | 628 | 0.7929936305732485 | 0.7922665224213865 | [18, 0, 38, 39, 35, 498] |
| total | 4601 | 0.6579004564225168 | 0.6576980424330509 | N/A |
FER-2013 and Ryerson Audio-Visual Database (RAVD). All FER-2013 images are used, and to achieve a balance among all labels, face images croped from RAVD video frames are used to fill the gap.
The training takes the pretrained parameters provided by the github repo: https://github.com/atulapra/Emotion-detection. Because we have 6 catergory instead of 7, we discard the parameters of the last layer, and append a Softmax layer with output_dim = 6. The training happens in three stages.
- In first stage (10 epochs), parameters from the repo are freezed, only new parameters are trained. Learning rate is set to 0.001 and batch size is set to 32.
- In the second stage (10 epochs), all parameters are trained. Learning rate is set to 0.0001 and batch size is set to 128.
- In the third stage (10 epochs), all parameters are trained. Batch size is increased significantly to create more stability among batches. Learning rate is set to 0.0001 and batch size is set to 1024.

https://github.com/XueweiWangBrooks/high-efficiency-face-detection